"I wanted to download manga to my ebook" or "A small introduction to Web Parsers in Python"
13-9-2024 20:23
I'm currently reading "The Climber" manga. It's about a guy falling in love with climbing(hence the name), and some internal battles he's having.

There are a few websites that serve manga online in Ukrainan, but unfortunately a lot of them do not allow/have the feature of downloading it. And I have a crappy EBook that I would like to read manga on, hopefully to put less strain on my eyes.

I've already got a "not-that-good" eyesight tbh🫠
So, armed with that wish, I decided to make a few parsers for manga websites.
I'll document the process I went through for zenko.online. So - first, I've found a title I'm interested in reading - this time it's "Look back" from Tatsuki Fujimoto, author of "Chainsaw Man". (there is an anime adaptation of it, but I wanted to check out the original)
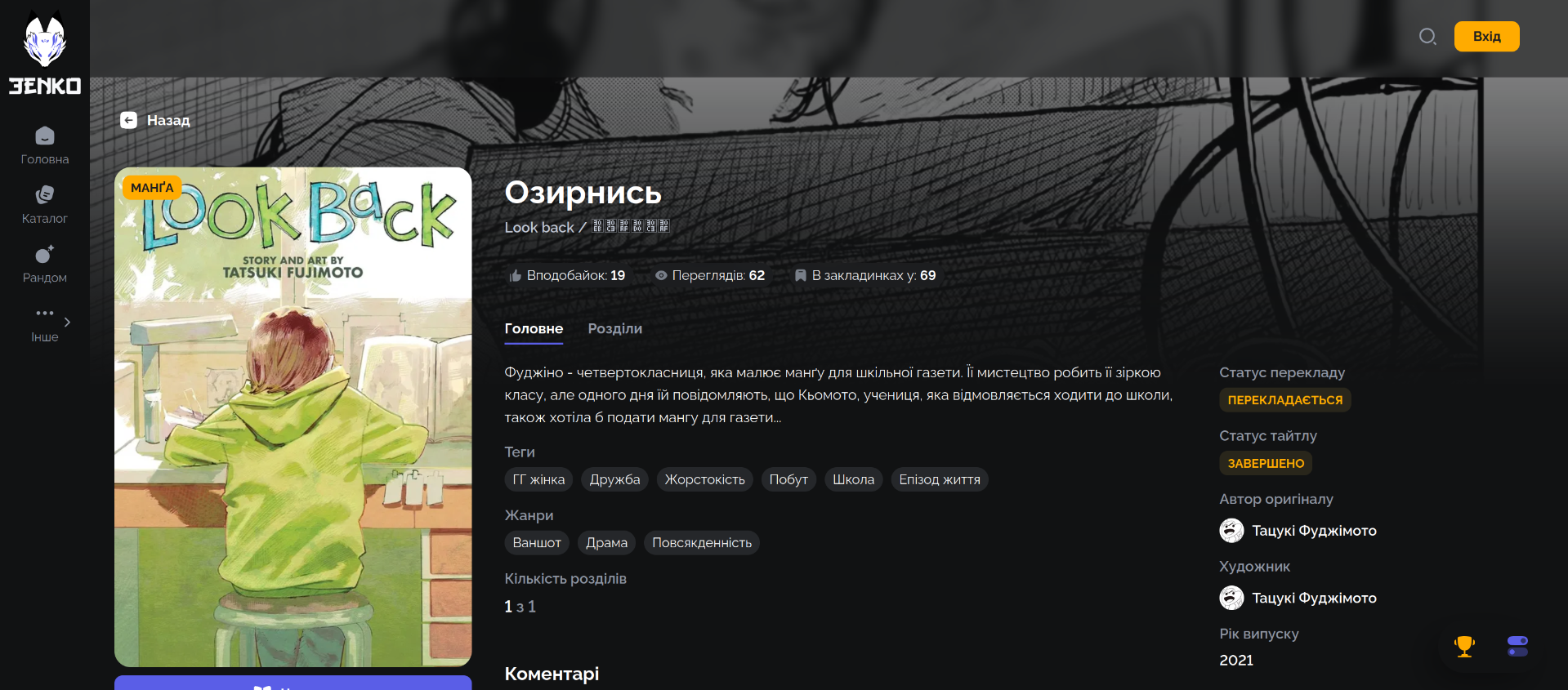
So, what I do to create a parser - I go to the page I want to parse, and then check out the requests in dev tools.
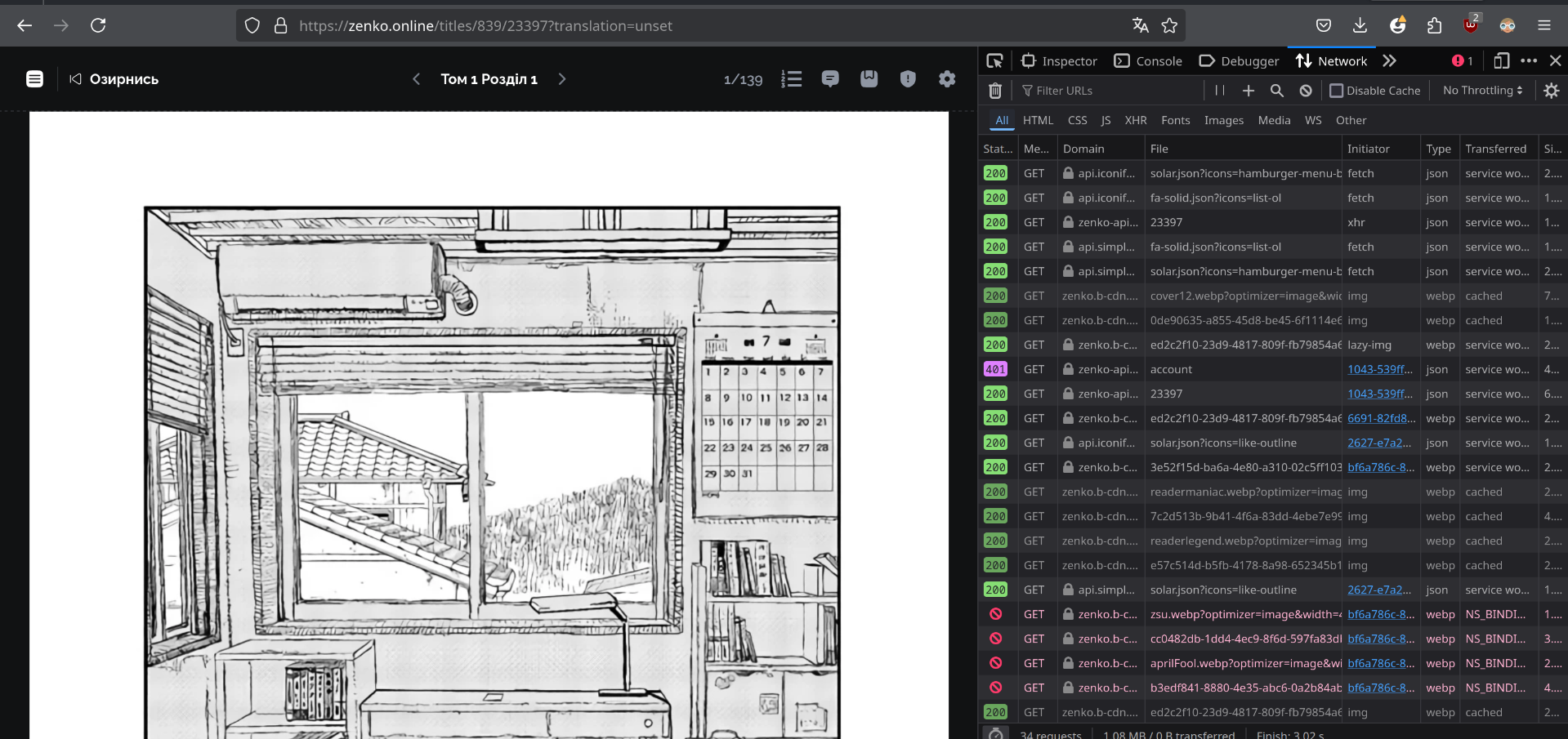
And right away I see a request that has "pages" field as part of it's response!
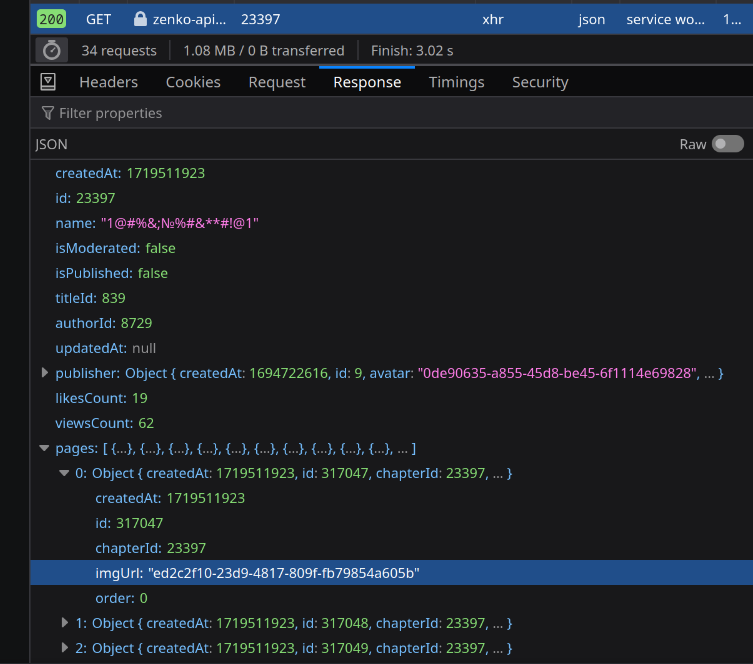
And if I check out the other requests - I can see that the imgUrl from that pages response has a corresponding request for an image.
So all I have to do now is to recreate those requests programmatically and I'll be able to download all manga pages.
My language of choise here is Python, but realistically probably any language you can think of has similar libraries. With zenko I'm lucky and am able to just use their API to download page data. With manga.in.ua, for example, the process is not as straightforward, as they are not using regular RESTful APIs, and got some bs with parts of page returned to user.
ZENKO_API_URL = "https://zenko-api.onrender.com" def download_zenko_chapter(chapter_id: str): chapter = requests.get(f"{ZENKO_API_URL}/chapters/{chapter_id}").json() pages_data = chapter["pages"] images = [] for page in pages_data: images.append(write_zenko_data(page["imgUrl"]))
so, getting all the chapter's images is quite easy:
- make a request to their chapter endpoint
- get the pages field, and collect the images urls.
- download each image and save it.
This process is very similar for other manga websites, so I've created a separate method specifically with the purpose of downloading images by their URLs, and then saving them into temp folder.
def write_image_data(imgId: str, imgUrl: str): result = requests.get(imgUrl) filename = f"temp/{imgId if imgId.endswith('.png') else f'{imgId}.png'}" with open(filename, "wb+") as file: file.write(result.content) return filename
And now for the saving to pdf - since this is something I expect I will need for the other manga websites, I've created a method:
from PIL import Image def save_to_pdf(filename, image_files: list[str]): images = [Image.open(f).convert("RGB") for f in image_files] pdf_path = f"result/{filename}" images[0].save( pdf_path, "PDF", resolution=100.0, save_all=True, append_images=images[1:] ) return filename
Most of it was written with ChatGPT, but a summary - it loads all the image files, and then saves them via PIL save method as PDF. I'd like to note the elegant way of adding all images to append_images via slicing.
small note here is that new PIL is called
Pillow. I believe it was previously PIL, and got abandoned. Pillow pip page
So, the whole download_zenko_chapter method would look like:
def download_zenko_chapter(chapter_id: str): chapter = requests.get(f"{ZENKO_API_URL}/chapters/{chapter_id}").json() pages_data = chapter["pages"] images = [] for page in pages_data: imgId = page["imgUrl"] imgUrl = f"{ZENKO_PROXY_URL}/{imgId}?optimizer=image&width=auto&quality=70&height=auto" images.append(write_image_data(imgId, imgUrl)) save_to_pdf(f"{chapter['name']}.pdf", images)
Now, I'd like to note a few things I didn't mention here if you are following this guide - you will want to add removal of temp images after the script has created the pdf, and think how to get the chapter id. Guess this is sorta homework in case anyone is actually trying to do this - you could use something like argparse library if you are also doing this in python, or create a more elegrant frontend solution. The world is yours =)
But there was no pain and suffering in that, so how about we take a look at another service that has a worse API - manga.in.ua.

Upon clicking "Start reading", a request to controller.php is sent, and afterwards pages are loaded in while scrolling.
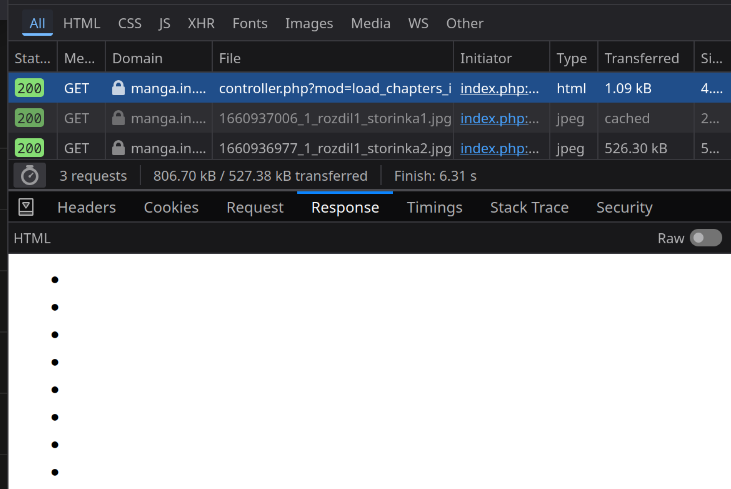
Looking into that request - it returns an html page with li elements. Here is a response sample
<ul class="xfieldimagegallery loadcomicsimages"> <li><img data-src="https://manga.in.ua/uploads/posts/page-1.jpg" alt=""></li> ... <li><img data-src="https://manga.in.ua/uploads/posts/last-page.jpg" alt=""></li> </ul>
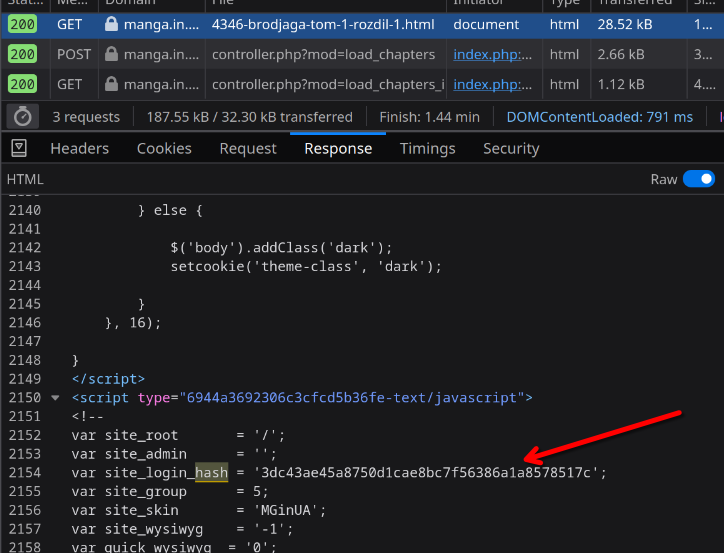
So we need to just redo this request to controller.php in our script, get those image data-src attributes and we're good to go? As it turns out, not quite - that controller request has a parameter user_hash, which might depend on the country request came from. And that hash is part of js script on pretty much any main page.
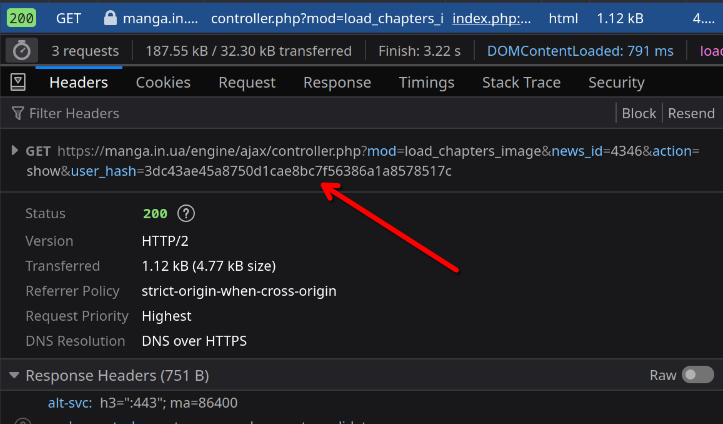
So the correct course of action would be to:
- Make a regular request to manga.in.ua and get user_hash
- Make a request to
controller.phpwith the hash and get image urls - Collect all pages and assemble a pdf(something already doable with current state of script)
With that in mind, here are a few methods that do this:
import re def get_manga_in_ua_hash(): home_page = requests.get("https://manga.in.ua").text login_hash = r".*site_login_hash = \'(?P<login_hash>.+)\'.*" match = re.search(login_hash, home_page) if not match: return False return match.group("login_hash")
This is the function to get the user hash^ The parsing is a little more complicated - it is using regex expression to extract the user hash from home page.
Function to parse controller.php response and extract the image urls. It is done via BeautifulSoup library:
#where the parsing magic happens def get_manga_in_ua_pages_data(chapter_url: str): soup = BeautifulSoup(requests.get(chapter_url).text, "html.parser") page_imgs = soup.find_all("img") page_urls = [] for page_img in page_imgs: page_urls.append(page_img["data-src"]) return page_urls
This library is made specifically for parsing, and as can be seen - I am using it's functions to access varios DOM objects.
And the rest of the script to assemble pdf:
BASE_CHAPTER_URI="https://manga.in.ua/engine/ajax/controller.php?mod=load_chapters_image" user_hash = get_manga_in_ua_hash() chapter_url = f"{BASE_CHAPTER_URI}&news_id={chapter_id}&action=show&user_hash={user_hash}" page_urls = get_manga_in_ua_pages_data(chapter_url) pages = [] for page_url in page_urls: page_id = str(uuid.uuid4()) pages.append(write_image_data(page_id, page_url)) file_name = manga_name + ".pdf" save_to_pdf(file_name, pages)
manga_name can be resolved from given manga chapter to download url 😉, but I leave the way of parsing it to you.
There might be a part 2 of this tutorial walking through integration of this script into java service with message queues and Docker.
